
Understanding the Concept of Learning

Hello there! 👋 I curate technical and non-technical articles.
According to Wikipedia, Learning is the process of acquiring new understanding, knowledge, behaviors, skills, values, attitudes, and preferences. The ability to learn is possessed by humans, animals, and some machines. Yes, that’s right, Machines!
You probably know what machine learning is all about or perhaps, you have no clue as to what it is. 🤷♀️ Care to know how the magic works?
In simple terms, Machine Learning (ML) is automated learning with little or no human intervention. It involves programming computers so that they learn from the available inputs. The main purpose of machine learning is to explore and construct algorithms that can learn from the previous data and make predictions on new inputs.
What is Supervised Learning?
This is similar to a teacher-student relationship. There is a teacher who guides the student to learn from books and other materials. The student is then tested and if correct, the student passes ✅. Otherwise, the teacher corrects the student and makes the student learn from past mistakes. This is the basic principle of Supervised Learning which involves building a machine learning model that is based on labeled data samples. It deals with learning a function from the available training data, it analyzes the data and produces a derived function that can be used for mapping new examples. Common examples include classifying emails into spam and non-spam categories, labeling webpages based on their content, voice/speech recognition, etc.
This type of learning is important because it gives the algorithm learning experience which can be used to output predictions for new unseen data. This experience also helps in optimizing the performance of the algorithm and real-world computations can also be taken care of by the supervised learning algorithms.
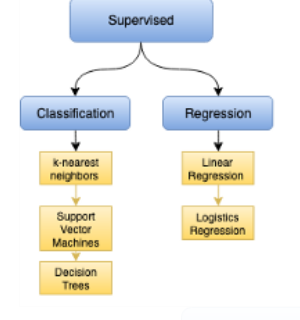
Supervised learning can be classified into two categories:
Regression: A regression problem is when the output variable is a real value. It is usually a number such as “money” or “weight”.
Classification on the other hand is the type of learning where the algorithm needs to map the new data that is obtained from any one of the two classes in the dataset. The classes need to be mapped to either 1 or 0 which in real-life is translated to "Yes" or "No", “disease” or “no disease” and so on. The output will be either one of the classes and not a number as it was in Regression.
Some of the algorithms include;
Linear Regression
Logistic Regression
Decision Tree
Naive Bayes Classifier
Support Vector Machines (SVM)
Other applications of Supervised Learning includes;
BioInformatics: One of the well-known applications of Supervised Learning because of its frequent use in our day-to-day lives, such as the use of facial recognition in smartphones, fingerprint sensing, etc.
Speech Recognition: The kind of application where you teach the algorithm about your voice and it will be able to recognize you. For example; Google Assistant and Siri.
Spam Detection: This is applied where fake or computer-based messages and emails are to be blocked. For example; Google mail has an algorithm that learns the different keywords that might pass off as fake messages, e.g “You have won…” and it blocks those messages directly. In some apps, you can select the keywords, and messages containing those words will be blocked.
Object Recognition: This is used where you need to identify an object or image. You have a huge dataset which you use to teach your algorithm and this can be used to recognize a new instance. For example an image search.
Unsupervised Learning
Unsupervised learning is the training of machine using information that is neither classified nor labeled and allowing the algorithm to act on that information without guidance. Here the task of the machine is to group unsorted information according to similarities, patterns, and differences without any prior training of data. Unlike supervised learning, no teacher is provided; this means no training will be given to the machine. The algorithm draws its conclusion by finding patterns or groupings in the dataset.
This type of learning can be applied in data mining for pattern finding and sequencing. Also, in medical imaging, object recognition, and genetic clustering. Depending on the problem at hand, the unsupervised learning model can organize the data in different ways.
Clustering: Here similar items are grouped, and patterns are formed. This helps to understand similarities in particular or various groups. For example, grouping customers by their purchasing behavior, trends in browsing patterns can be identified and clustered by;
How many people of the age group 20-30 years check their Facebook accounts during day time?
What are the most trending topics on Instagram and Twitter etc? The most popular clustering algorithms used today are K-mean clustering and Hierarchical clustering.
Association: This helps to find relationships between the variables in the dataset, such as people that buy X also tend to buy Y. For example, customers who recently booked a flight ticket might also need an airport pick-up and hotel accommodation, or a person who just bought a laptop online may need a laptop bag or a stand.
Note: In addition, the pros and cons of supervised vs unsupervised machine learning depend majorly on the exact learning algorithm you use.
Semi-supervised Learning
When we have some learning samples labeled and others are not, it is semi-supervised learning. It uses a large amount of unlabeled data for training and a small amount of labeled data for testing. Semi-supervised learning is applied in cases where it is expensive to fully acquire a labeled dataset and more practical to label a smaller subset. For example, it often requires skilled experts to label certain remote sensing images, while acquiring unlabeled data is relatively easy.
Reinforcement Learning
In this technique, the model keeps on increasing its performance using reward feedback to learn the behavior or pattern. The learning data give feedback so that the system adjusts to dynamic conditions in order to achieve a certain objective. The system evaluates its performance based on the feedback responses and reacts accordingly.
For example in video games, you are expected to complete a level and earn a badge, defeat the bad guy probably in a certain number of moves and earn a bonus, step into a trap, and Boom! 💥 Game over! These cues help players learn how to improve their performance for the next game. Without this feedback, they would just take random actions around the game environment with hopes of advancing to the next level.
Reinforcement learning operates on the same principle. To make its choices, the model relies on learnings from past feedback while exploring new tactics. This involves a long-term strategy, it is an iterative process, that is, the more rounds of feedback, the better the model becomes. This technique is especially useful in training robots that make a series of decisions in tasks like steering an autonomous vehicle (self-driving cars) or managing inventory in a warehouse.
Also, just like students in school learning, every algorithm learns differently. But with the diversity of approaches available, what matters most is picking the best way to help your model learn in relation to what you are trying to achieve.
Conclusion
As a field of science, machine learning shares common concepts with other disciplines such as statistics, informatics, and others. The objective is to program machines to learn and act on their own. However, the purpose is not to build an automated duplication of intelligent behavior, rather using the power of computers to complement and supplement human intelligence. For example, machine learning programs can scan and process huge databases detecting patterns that are beyond the scope of human perception.
References
https://www.guru99.com/supervised-machine-learning.html
https://www.geeksforgeeks.org/regression-classification-supervised-machine-learning/?ref=lbp



